Real-World Nextflow on GCP
Adding to the QuickStart for Google Batch
One of my bioinformatics clients needs me to help her migrate her HPC-based custom Nextflow workflow to Google Cloud. To be able to guide her, I started by running the GCP Nextflow on Google Batch quickstart. Google’s example “runs a sample bioinformatics pipeline that quantifies genomic features from short read data using RNA-Seq.”
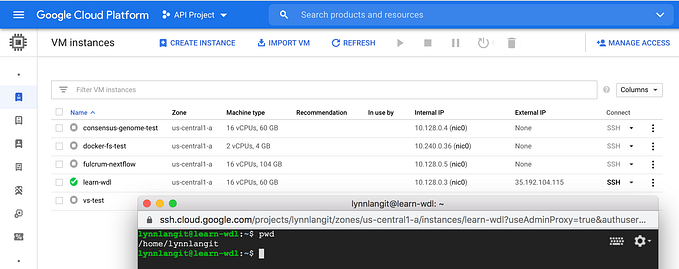
While I was able to successfully run the sample as written, using Google cloud shell as my client, I found myself wanting to test out more available Google Batch features that I believe will provide value for my Nextflow production situation. Also I drew a diagram (shown below) of my understanding of what I was testing.

Conveniently, Google cloud shell includes the Google Cloud SDK, docker binaries and the JVM (Java) runtime which are all required to run this test, so I installed nothing other than Nextflow in cloud shell.
I successfully ran the basic sample using the supplied profile parameter using this command in cloud shell: ../nextflow run nextflow-io/rnaseq-nf -profile gcb
More Configs
The example uses a profile configuration for Google Cloud Batch (aliased as gcb) in a stanza in the Nextflow-required nextflow.config file as shown below.
gcb {
params.transcriptome = 'gs://rnaseq-nf/data/ggal/transcript.fa'
params.reads = 'gs://rnaseq-nf/data/ggal/gut_{1,2}.fq'
params.multiqc = 'gs://rnaseq-nf/multiqc'
process.executor = 'google-batch'
process.container = 'quay.io/nextflow/rnaseq-nf:v1.1'
workDir = 'gs://BUCKET_NAME/WORK_DIRECTORY'
google.region = 'us-central1'
}
...I created a list of Google Batch parameters that I commonly used with ‘raw Batch’ (i.e. not using Nextflow) bioinformatics workloads and wondered which of these parameters would be supported by Nextflow for Google Batch. Here’s my initial shortlist:
- Set `Project Name` (obvious, but curiously not listed in the sample)
- Use GCE `SPOT` VM instances for worker nodes (Up to 90% cheaper than on-demand instances, so key for this scenario!)
- Configure `maxRetries` for tasks using SPOT instances (to retry rather than fail the task/job if a worker VM node is preempted)
- Upload the reference container my Artifact Registry and use (see detail in the last section). To start I just used the public container for
rnaseqhosted inquay.io.
Shown below is my updated nextflow.config profile stanza. My test job runs ok, EXCEPT if a worker node gets preempted. Initially, I didn’t set maxRetries and I had a task and job failure on node preemption.
gcb {
params.transcriptome = 'gs://rnaseq-nf/data/ggal/transcript.fa'
params.reads = 'gs://rnaseq-nf/data/ggal/gut_{1,2}.fq'
params.multiqc = 'gs://rnaseq-nf/multiqc'
process.executor = 'google-batch'
process.container = '<MY_ARTIFACT_REGISTRY>/images/rnaseq:1.0'
process.label = 'rnalangit'
process.maxRetries = 3
workDir = 'gs://batch-demo-data-compute/nf-rnaseq-spot-results'
google.region = 'us-central1'
google.project = '<MY_PROJECT_NAME>'
google.batch.spot = true
}Nodes Matter
I was happy to see that (shown below) my test job used are the GCE (Compute Engine) VM worker SPOT nodes. Of note is that the machine family isn’t configured and the selected type is g1-small .
In my experience, paying attention to workload requirements and manually configuring the best-fit machine family (and type) yields best value results in scaling bioinformatics analysis jobs.
- If the nodes are too small, the tasks take too long and have a greater likelihood of getting preempted, which makes tasks take even longer
- If the nodes are too big, there are fewer available (and in the SPOT pool), so task startup can take longer. Also if nodes are under-utilized, then you are literally overpaying for compute resources.
- If the nodes are too obscure, there are fewer available (and in the SPOT pool), so task startup can take longer. Also if nodes are under-utilized, then you are literally overpaying for compute resources.

Reading the Docs
Next I read the Nextflow on Google Batch documentation, which includes more extensive information about support for Google Batch parameters.
“The integration with Google Batch is a developer preview feature. Currently, the following Nextflow directives are supported:”
Next Steps
What I want/need to do next is to update my nextflow.config file to use the Google Batch features that my client needs for her workload. These include the following:
- Configure retry behavior if worker node SPOT is preempted
- Configure machine type families or instance template including GPU families
- Test task-level configuration syntax (CPU, RAM…)
- Configure OS disk and working disks — types and sizes
Figuring out valid configuration files, is, however, only part of the work involved in guiding my research colleague to migrating her NF-based workload from HPC to Google Batch. In the next section, I highlight top enterprise considerations that will also apply here.
Enterprise Considerations
In production, I’ll need to configure NF-on-Batch to use a named GCP IAM service account (rather than the default compute engine service account) and also verify associated role-based IAM permissions.
From Google’s docs…
“To get the permissions that you need to complete this tutorial, ask your administrator to grant you the following IAM roles:
- Batch Job Editor (
roles/batch.jobsEditor) on the project - Service Account User (
roles/iam.serviceAccountUser) on the job's service account, which for this tutorial is the Compute Engine default service account - Storage Object Admin (
roles/storage.objectAdmin) on the project”
I’ll also need to set allowExternalIP to false for the worker nodes. And I’ll need to specify a named GCP project network and subnet, rather than using the default values for testing.
I tested using the public docker rnaseq container image (hosted in quay.io), referenced in the sample. I also pulled, tagged and pushed a version of this container to my GCP Artifact Registry. As is is typical with open source containers, the container I found, included a number of critical security vulnerabilities. So, I’ll need to build a process to scan and remediate open source tool containers for my client. Shown below are my GCP Artifact Registry scanning results.

Finally, I’ll want to verify that the GCP service quotas are adequate for my client to be able to scale her workload to meet her analysis needs. I’ve noticed that workloads that need GPUs need real-world scale testing and quota increases most often.
So, I will work next to translate the NF docs into a more extensive working sample. I will publish/update this work on my GitHub Repo as an evolving sample set of configuration example files.
Results
In case you are wondering the example rnaseq Nextflow-on-Batch example runs a multi-step workflow and produces several outputs, including a MultiQC html report. Sample shown below. I find it helpful to ‘begin with end in mind’ and I like to see what my bioinformatics colleagues want as output to the processes we build together.